A Short History of Facial Recognition
Demystifying Clearview AI Blog Series (Part 1)
Table of Contents
Previous: The End of Privacy as We Know It
Next: Collecting Data for Deep Learning Development

From Panoramic to the World Wide Web
Facial recognition in the US goes as far back as the 1960s when mathematician and computer scientist Woodrow “Woody” Bledsoe piqued the Central Intelligence Agency’s interest with his research in automated reasoning and artificial intelligence. To market his research, Woody founded Panoramic Research Incorporated with the stated mission of “trying out ideas which would ‘move the world.’”
Much of Panoramic’s history is shrouded in secrecy. However, Freedom of Information Request and declassified documents show that since inception Panoramic had received numerous projects and funding through CIA front companies such as the Medical Sciences Research Foundation and the King-Hurley Research Group. In 2005 the CIA declassified a 1968 document that mentions an “external contract” funneled to Panoramic for a facial-recognition system that would reduce search time by a hundredfold. Thus began the US government’s most explicit foray into facial recognition technology.
As part of a collaboration with the Applied Physics Laboratory at the Stanford Research Institute (currently known as SRI International), Panoramic ultimately developed a machine that was “vastly superior” and “dominated” humans in facial recognition.

In the early days, facial recognition technology wasn’t very effective. Back then, even the idea of recognizing as few as ten faces was breathtakingly ambitious. Panoramic’s research datasets started with as little 122 photographs, growing slowly to 2,000 images over several years. Such data limitations were primarily due to the manual labor required to preprocess pictures as well as the lack of high quality publicly available images.
Two of the most significant breakthroughs in facial recognition technology arrived in the early 2000s with the ubiquity of Google, Facebook, and the World Wide Web.

Since being founded in 1998, Google’s corporate mission has always been to “organize the world’s information and make it universally accessible and useful.” Meanwhile, Facebook passionately championed the idea of “making the world more open and connected.”
By 2008 Google was processing upwards of 8 billion searches a year, and Facebook had connected over 150 million users worldwide. The combination of those two platforms and various others on the world wide web effectively overcame the dataset and preprocessing limitations of Woody’s earlier work.

From the FBI to Clearview
The Criminal Justice Information Services (CJIS) Division, the FBI’s largest division, was established in 1992 to serve as the focal point and central repository for criminal justice information services such as fingerprint and face identification.
In 2008, as mandated by the Privacy Act of 1974, the FBI’s CJIS Division released a Privacy Impact Assessment (PIA) for the first time detailing its Next Generation Identification Interstate Photo System (NGI-IPS). Back in 2008, it was revealed the FBI’s NGI-IPS consisted primarily of a few million criminal “mug shots” and other identifying images such as scars, marks, and tattoos.
The FBI first launched the facial recognition component of its NGI-IPS in 2011 with a database of over 10 million images. As the NGI-IPS database grew over the years, the FBI, in violation of federal and agency laws, failed to provide updated PIAs.

In 2016 the Government Accountability Office (GAO) eventually revealed that in addition to 30 million mug shots from criminal databases, the FBI had gained access to as many as 412 million non-criminal civilian images as part of its database. Those images included driver license photos from 16 states, the State Department’s visa and passport database, and the Defense Department’s biometric database.
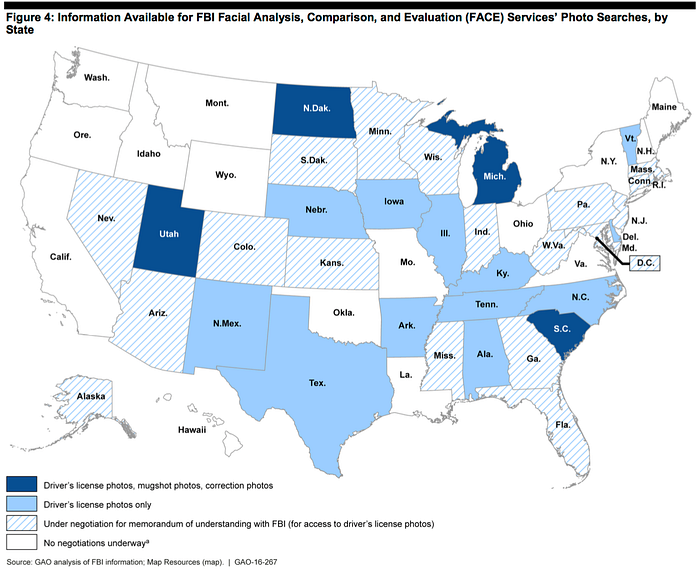
With the controversy surrounding the GAO’s report, the FBI shifted to partnering with private entities such as Microsoft, Amazon, and Google to license facial recognition technologies instead of developing such systems in-house. Despite that shift, the FBI’s facial recognition image database continued to grow.
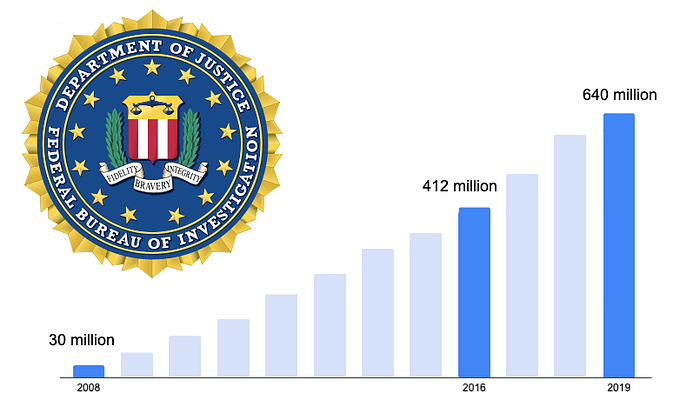
Most recently, at a 2019 House Oversight Committee hearing, the FBI confirmed that its image database had grown to over 640 million photos. That database now included driver license photos from 21 states, including states that do not have laws explicitly allowing their driver license repositories to be used in facial recognition.
The 2019 hearing revealed very little about the FBI’s facial recognition system’s efficacy, and it’s compliance with constitutional obligations, or “the companies who lobby or communicate” with the FBI regarding the system.
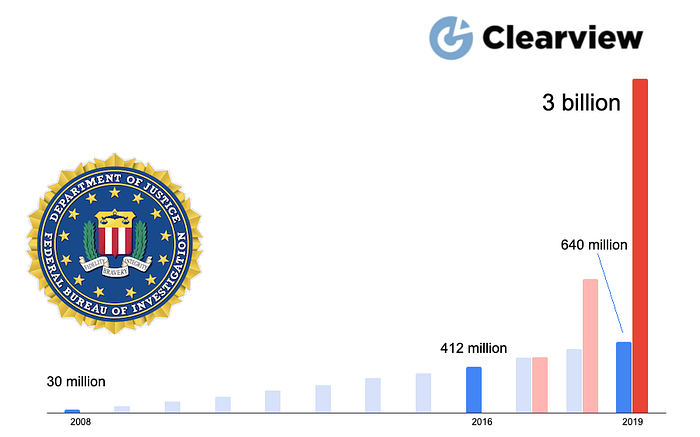
In contrast to the decades-long steady growth of the FBI’s disclosed image database from 10 million in 2011 to 640 million in 2019, Clearview’s image database grew undisclosed from hundreds of millions to several billion in less than three years. Such explosive growth is due to the World Wide Web as discussed previously and due to the nature of Deep Learning and Artificial Intelligence technologies in general.
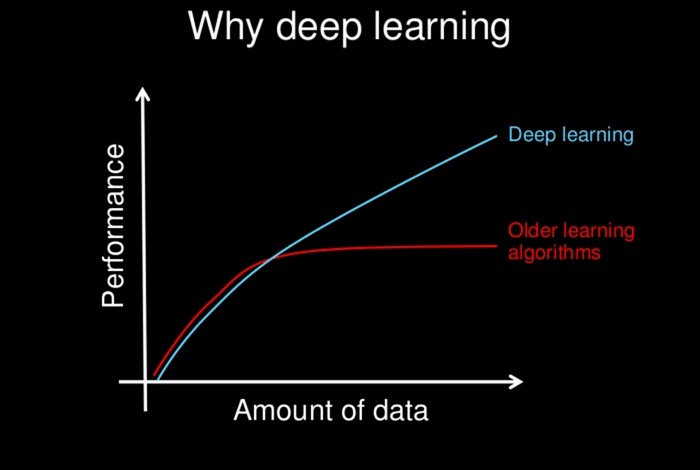
Most systems become less performant as the underlying dataset increases. Searching through 3 billion images would be slower and less effective than searching through 640 million images. With Deep Learning, the reality is different. Training a model and searching through a dataset happen separately, and images are often preprocessed into an intermediate format to speed up the process considerably.
As the size of the underlying training dataset grows, a Deep Learning model’s accuracy and performance will continue to improve. Such Deep Learning data performance scalability contrasts with classical Machine Learning models that plateau much sooner and tend to require more complex methods to improve accuracy.
References
Deep Learning vs Classical Machine Learning
Statement Before the Senate Judiciary Committee, Subcommittee on Privacy, Technology, and the Law
Smile, you’re in the FBI face-recognition database
Deep Learning vs Classical Machine Learning
FBI — Next Generation Identification
The FBI Has Access to Over 640 Million Photos of Us Through Its Facial Recognition Database
FBI’s use of facial recognition software in criminal investigations is under fire again
New Report: FBI Can Access Hundreds of Millions of Face Recognition Photos
Re: FBI Next Generation Identification System (NGI)
FBI Keeps Secret How Massive Facial Recognition Database Will Work
FBI Facial Recognition Database to Have 52 Million Photos of Americans
The Faces of Facebook app shows all 1.2 billion users
The Secret History of Facial Recognition
